85 posts tagged “gemini”
The Gemini family of multimodal LLMs developed by Google DeepMind.
2025
Gemini 2.5 Models now support implicit caching.
I just spotted a cacheTokensDetails key in the token usage JSON while running a long chain of prompts against Gemini 2.5 Flash - despite not configuring caching myself:
{"cachedContentTokenCount": 200658, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 204082}], "cacheTokensDetails": [{"modality": "TEXT", "tokenCount": 200658}], "thoughtsTokenCount": 2326}
I went searching and it turns out Gemini had a massive upgrade to their prompt caching earlier today:
Implicit caching directly passes cache cost savings to developers without the need to create an explicit cache. Now, when you send a request to one of the Gemini 2.5 models, if the request shares a common prefix as one of previous requests, then it’s eligible for a cache hit. We will dynamically pass cost savings back to you, providing the same 75% token discount. [...]
To make more requests eligible for cache hits, we reduced the minimum request size for 2.5 Flash to 1024 tokens and 2.5 Pro to 2048 tokens.
Previously you needed to both explicitly configure the cache and pay a per-hour charge to keep that cache warm.
This new mechanism is so much more convenient! It imitates how both DeepSeek and OpenAI implement prompt caching, leaving Anthropic as the remaining large provider who require you to manually configure prompt caching to get it to work.
Gemini's explicit caching mechanism is still available. The documentation says:
Explicit caching is useful in cases where you want to guarantee cost savings, but with some added developer work.
With implicit caching the cost savings aren't possible to predict in advance, especially since the cache timeout within which a prefix will be discounted isn't described and presumably varies based on load and other circumstances outside of the developer's control.
Update: DeepMind's Philipp Schmid:
There is no fixed time, but it's should be a few minutes.
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
Create and edit images with Gemini 2.0 in preview (via) Gemini 2.0 Flash has had image generation capabilities for a while now, and they're now available via the paid Gemini API - at 3.9 cents per generated image.
According to the API documentation you need to use the new gemini-2.0-flash-preview-image-generation model ID and specify {"responseModalities":["TEXT","IMAGE"]} as part of your request.
Here's an example that calls the API using curl (and fetches a Gemini key from the llm keys get store):
curl -s -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key=$(llm keys get gemini)" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [ {"text": "Photo of a raccoon in a trash can with a paw-written sign that says I love trash"} ] }], "generationConfig":{"responseModalities":["TEXT","IMAGE"]} }' > /tmp/raccoon.json
Here's the response. I got Gemini 2.5 Pro to vibe-code me a new debug tool for visualizing that JSON. If you visit that tool and click the "Load an example" link you'll see the result of the raccoon image visualized:

The other prompt I tried was this one:
Provide a vegetarian recipe for butter chicken but with chickpeas not chicken and include many inline illustrations along the way
The result of that one was a 41MB JSON file(!) containing 28 images - which presumably cost over a dollar since images are 3.9 cents each.
Some of the illustrations it chose for that one were somewhat unexpected:

If you want to see that one you can click the "Load a really big example" link in the debug tool, then wait for your browser to fetch and render the full 41MB JSON file.
The most interesting feature of Gemini (as with GPT-4o images) is the ability to accept images as inputs. I tried that out with this pelican photo like this:
{kind=link}
cat > /tmp/request.json << EOF { "contents": [{ "parts":[ {"text": "Modify this photo to add an inappropriate hat"}, { "inline_data": { "mime_type":"image/jpeg", "data": "$(base64 -i pelican.jpg)" } } ] }], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"]} } EOF # Execute the curl command with the JSON file curl -X POST \ 'https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-preview-image-generation:generateContent?key='$(llm keys get gemini) \ -H 'Content-Type: application/json' \ -d @/tmp/request.json \ > /tmp/out.json
And now the pelican is wearing a hat:

llm-prices.com.
I've been maintaining a simple LLM pricing calculator since October last year. I finally decided to split it out to its own domain name (previously it was hosted at tools.simonwillison.net/llm-prices), running on Cloudflare Pages.

The site runs out of my simonw/llm-prices GitHub repository. I ported the history of the old llm-prices.html file using a vibe-coded bash script that I forgot to save anywhere.
I rarely use AI-generated imagery in my own projects, but for this one I found an excellent reason to use GPT-4o image outputs... to generate the favicon! I dropped a screenshot of the site into ChatGPT (o4-mini-high in this case) and asked for the following:
design a bunch of options for favicons for this site in a single image, white background

I liked the top right one, so I cropped it into Pixelmator and made a 32x32 version. Here's what it looks like in my browser:

I added a new feature just now: the state of the calculator is now reflected in the #fragment-hash URL of the page, which means you can link to your previous calculations.
I implemented that feature using the new gemini-2.5-pro-preview-05-06, since that model boasts improved front-end coding abilities. It did a pretty great job - here's how I prompted it:
llm -m gemini-2.5-pro-preview-05-06 -f https://www.llm-prices.com/ -s 'modify this code so that the state of the page is reflected in the fragmenth hash URL - I want to capture the values filling out the form fields and also the current sort order of the table. These should be respected when the page first loads too. Update them using replaceHistory, no need to enable the back button.'
Here's the transcript and the commit updating the tool, plus an example link showing the new feature in action (and calculating the cost for that Gemini 2.5 Pro prompt at 16.8224 cents, after fixing the calculation.)
Gemini 2.5 Pro Preview: even better coding performance. New Gemini 2.5 Pro "Google I/O edition" model, released a few weeks ahead of that annual developer conference.
They claim even better frontend coding performance, highlighting their #1 ranking on the WebDev Arena leaderboard, notable because it knocked Claude 3.7 Sonnet from that top spot. They also highlight "state-of-the-art video understanding" with a 84.8% score on the new-to-me VideoMME benchmark.
I rushed out a new release of llm-gemini adding support for the new gemini-2.5-pro-preview-05-06 model ID, but it turns out if I had read to the end of their post I should not have bothered:
For developers already using Gemini 2.5 Pro, this new version will not only improve coding performance but will also address key developer feedback including reducing errors in function calling and improving function calling trigger rates. The previous iteration (03-25) now points to the most recent version (05-06), so no action is required to use the improved model
I'm not a fan of this idea that a model ID with a clear date in it like gemini-2.5-pro-preview-03-25 can suddenly start pointing to a brand new model!
I used the new Gemini 2.5 Pro to summarize the conversation about itself on Hacker News using the latest version of my hn-summary.sh script:
hn-summary.sh 43906018 -m gemini-2.5-pro-preview-05-06
Here's what I got back - 30,408 input tokens, 8,535 output tokens and 3,980 thinknig tokens for a total cost of 16.316 cents.
8,535 output tokens is a lot. My system prompt includes the instruction to "Go long" - this is the first time I've seen a model really take that to heart. For comparison, here's the result of a similar experiment against the previous version of Gemini 2.5 Pro two months ago.
Update: The one time I forget to run my "Generate an SVG of a pelican riding a bicycle" test is the time that the model turns out to produce one of the best results I've seen yet!

Here's the transcript - 11 input tokens and 3,281 output tokens and 1,558 thinking tokens = 4.8404 cents.
I asked Gemini to describe that image:
llm -m gemini-2.5-pro-preview-05-06 \
-a https://static.simonwillison.net/static/2025/gemini-latest-pelican.jpg \
'describe image for alt text'
Here's what I got back. Gemini thought it had drawn a duck:
A cartoon illustration of a white duck with an orange beak riding a blue bicycle.
The duck has a large, oval white body and a smaller round head with a black dot eye. Its thin black wings act as arms, gripping the blue handlebars. One yellow-orange leg is visible, bent and pushing a grey pedal.
The bicycle has a blue frame with a distinctive cross-brace, a brown oval seat, and dark grey wheels with silver spokes. The entire image is set against a plain white background.
AI assisted search-based research actually works now

For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]In some tasks, AI is unreliable. In others, it is superhuman. You could, of course, say the same thing about calculators, but it is also clear that AI is different. It is already demonstrating general capabilities and performing a wide range of intellectual tasks, including those that it is not specifically trained on. Does that mean that o3 and Gemini 2.5 are AGI? Given the definitional problems, I really don’t know, but I do think they can be credibly seen as a form of “Jagged AGI” - superhuman in enough areas to result in real changes to how we work and live, but also unreliable enough that human expertise is often needed to figure out where AI works and where it doesn’t.
— Ethan Mollick, On Jagged AGI
llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]Image segmentation using Gemini 2.5

Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
[... 1,428 words]Start building with Gemini 2.5 Flash
(via)
Google Gemini's latest model is Gemini 2.5 Flash, available in (paid) preview as gemini-2.5-flash-preview-04-17.
Building upon the popular foundation of 2.0 Flash, this new version delivers a major upgrade in reasoning capabilities, while still prioritizing speed and cost. Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off. The model also allows developers to set thinking budgets to find the right tradeoff between quality, cost, and latency.
Gemini AI Studio product lead Logan Kilpatrick says:
This is an early version of 2.5 Flash, but it already shows huge gains over 2.0 Flash.
You can fully turn off thinking if needed and use this model as a drop in replacement for 2.0 Flash.
I added support to the new model in llm-gemini 0.18. Here's how to try it out:
llm install -U llm-gemini
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle'
Here's that first pelican, using the default setting where Gemini Flash 2.5 makes its own decision in terms of how much "thinking" effort to apply:

Here's the transcript. This one used 11 input tokens, 4,266 output tokens and 2,702 "thinking" tokens.
I asked the model to "describe" that image and it could tell it was meant to be a pelican:
A simple illustration on a white background shows a stylized pelican riding a bicycle. The pelican is predominantly grey with a black eye and a prominent pink beak pouch. It is positioned on a black line-drawn bicycle with two wheels, a frame, handlebars, and pedals.
The way the model is priced is a little complicated. If you have thinking enabled, you get charged $0.15/million tokens for input and $3.50/million for output. With thinking disabled those output tokens drop to $0.60/million. I've added these to my pricing calculator.
For comparison, Gemini 2.0 Flash is $0.10/million input and $0.40/million for output.
So my first prompt - 11 input and 4,266+2,702 =6,968 output (with thinking enabled), cost 2.439 cents.
Let's try 2.5 Flash again with thinking disabled:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 0

11 input, 1705 output. That's 0.1025 cents. Transcript here - it still shows 25 thinking tokens even though I set the thinking budget to 0 - Logan confirms that this will still be billed at the lower rate:
In some rare cases, the model still thinks a little even with thinking budget = 0, we are hoping to fix this before we make this model stable and you won't be billed for thinking. The thinking budget = 0 is what triggers the billing switch.
Here's Gemini 2.5 Flash's self-description of that image:
A minimalist illustration shows a bright yellow bird riding a bicycle. The bird has a simple round body, small wings, a black eye, and an open orange beak. It sits atop a simple black bicycle frame with two large circular black wheels. The bicycle also has black handlebars and black and yellow pedals. The scene is set against a solid light blue background with a thick green stripe along the bottom, suggesting grass or ground.
And finally, let's ramp the thinking budget up to the maximum:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 24576

I think it over-thought this one. Transcript - 5,174 output tokens and 3,023 thinking tokens. A hefty 2.8691 cents!
A simple, cartoon-style drawing shows a bird-like figure riding a bicycle. The figure has a round gray head with a black eye and a large, flat orange beak with a yellow stripe on top. Its body is represented by a curved light gray shape extending from the head to a smaller gray shape representing the torso or rear. It has simple orange stick legs with round feet or connections at the pedals. The figure is bent forward over the handlebars in a cycling position. The bicycle is drawn with thick black outlines and has two large wheels, a frame, and pedals connected to the orange legs. The background is plain white, with a dark gray line at the bottom representing the ground.
One thing I really appreciate about Gemini 2.5 Flash's approach to SVGs is that it shows very good taste in CSS, comments and general SVG class structure. Here's a truncated extract - I run a lot of these SVG tests against different models and this one has a coding style that I particularly enjoy. (Gemini 2.5 Pro does this too).
<svg width="800" height="500" viewBox="0 0 800 500" xmlns="http://www.w3.org/2000/svg"> <style> .bike-frame { fill: none; stroke: #333; stroke-width: 8; stroke-linecap: round; stroke-linejoin: round; } .wheel-rim { fill: none; stroke: #333; stroke-width: 8; } .wheel-hub { fill: #333; } /* ... */ .pelican-body { fill: #d3d3d3; stroke: black; stroke-width: 3; } .pelican-head { fill: #d3d3d3; stroke: black; stroke-width: 3; } /* ... */ </style> <!-- Ground Line --> <line x1="0" y1="480" x2="800" y2="480" stroke="#555" stroke-width="5"/> <!-- Bicycle --> <g id="bicycle"> <!-- Wheels --> <circle class="wheel-rim" cx="250" cy="400" r="70"/> <circle class="wheel-hub" cx="250" cy="400" r="10"/> <circle class="wheel-rim" cx="550" cy="400" r="70"/> <circle class="wheel-hub" cx="550" cy="400" r="10"/> <!-- ... --> </g> <!-- Pelican --> <g id="pelican"> <!-- Body --> <path class="pelican-body" d="M 440 330 C 480 280 520 280 500 350 C 480 380 420 380 440 330 Z"/> <!-- Neck --> <path class="pelican-neck" d="M 460 320 Q 380 200 300 270"/> <!-- Head --> <circle class="pelican-head" cx="300" cy="270" r="35"/> <!-- ... -->
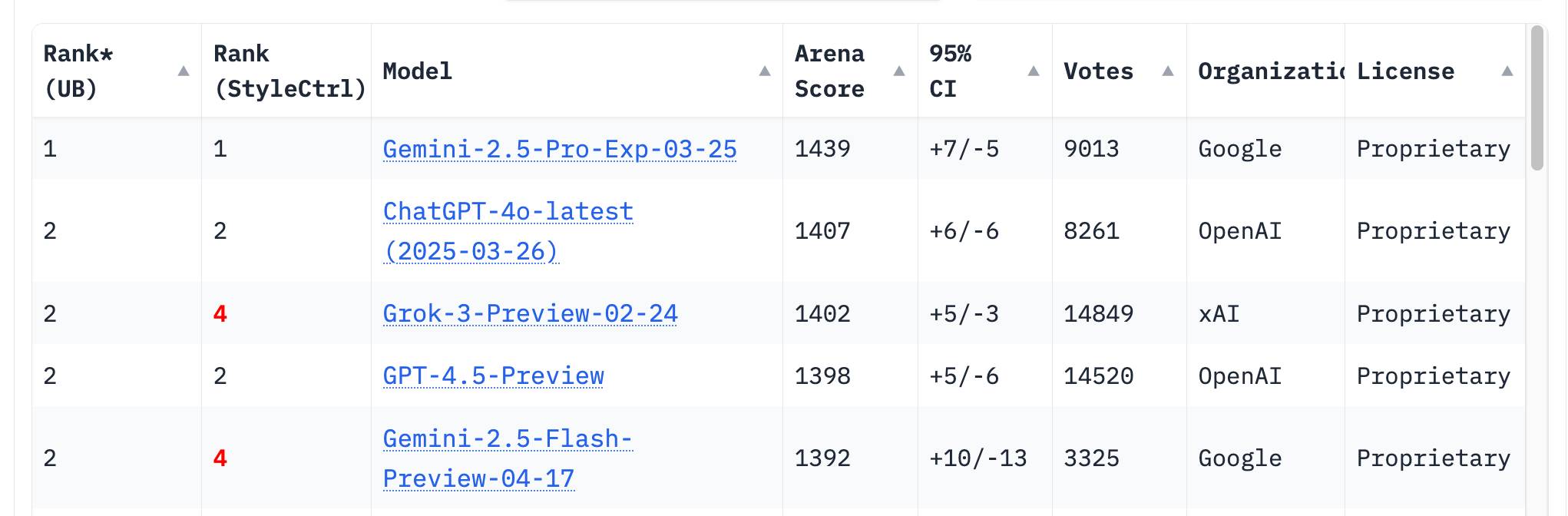
The LM Arena leaderboard now has Gemini 2.5 Flash in joint second place, just behind Gemini 2.5 Pro and tied with ChatGPT-4o-latest, Grok-3 and GPT-4.5 Preview.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
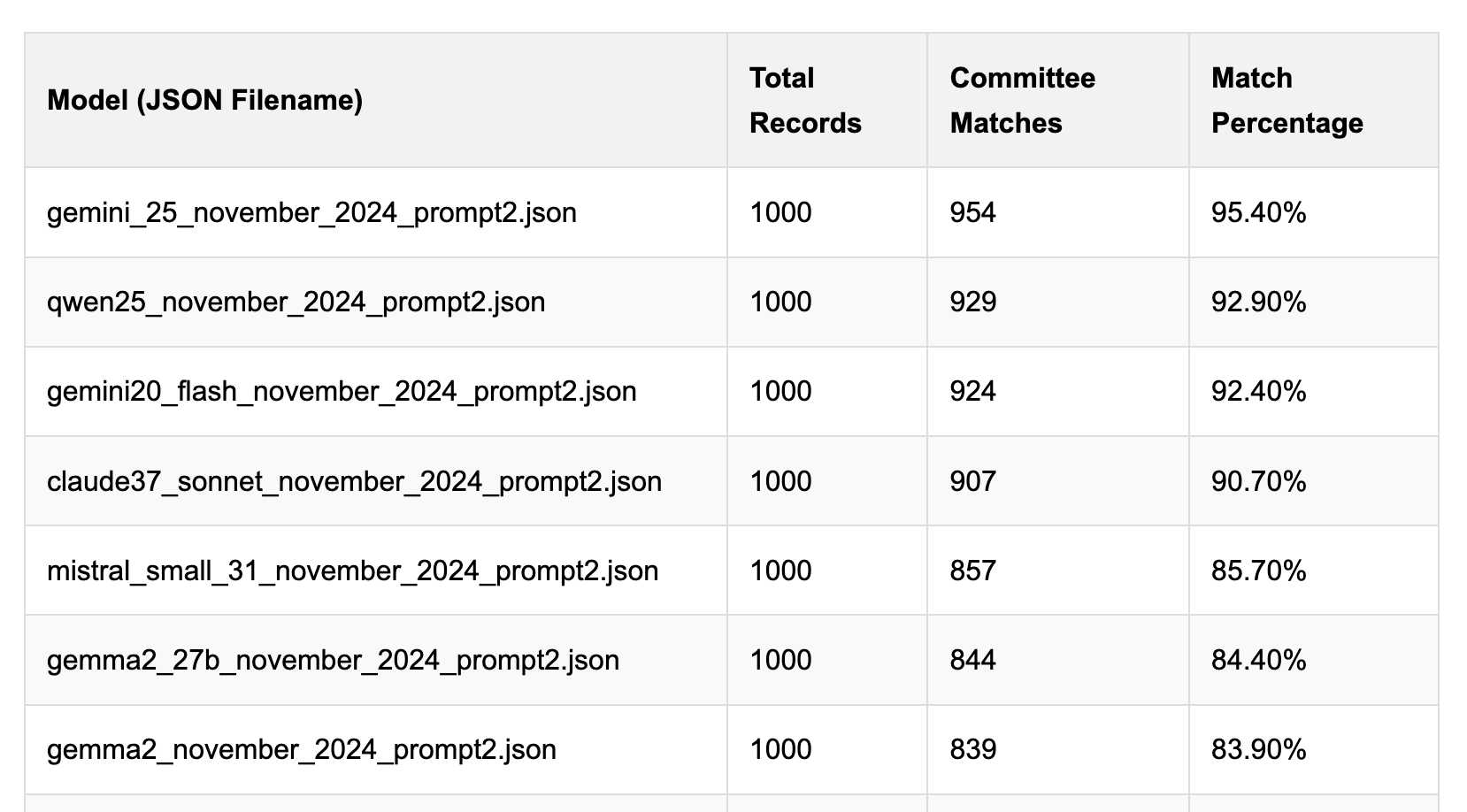
Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
Long context support in LLM 0.24 using fragments and template plugins

LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]Gemini 2.5 Pro Preview pricing (via) Google's Gemini 2.5 Pro is currently the top model on LM Arena and, from my own testing, a superb model for OCR, audio transcription and long-context coding.
You can now pay for it!
The new gemini-2.5-pro-preview-03-25 model ID is priced like this:
- Prompts less than 200,00 tokens: $1.25/million tokens for input, $10/million for output
- Prompts more than 200,000 tokens (up to the 1,048,576 max): $2.50/million for input, $15/million for output
This is priced at around the same level as Gemini 1.5 Pro ($1.25/$5 for input/output below 128,000 tokens, $2.50/$10 above 128,000 tokens), is cheaper than GPT-4o for shorter prompts ($2.50/$10) and is cheaper than Claude 3.7 Sonnet ($3/$15).
Gemini 2.5 Pro is a reasoning model, and invisible reasoning tokens are included in the output token count. I just tried prompting "hi" and it charged me 2 tokens for input and 623 for output, of which 613 were "thinking" tokens. That still adds up to just 0.6232 cents (less than a cent) using my LLM pricing calculator which I updated to support the new model just now.
I released llm-gemini 0.17 this morning adding support for the new model:
llm install -U llm-gemini
llm -m gemini-2.5-pro-preview-03-25 hi
Note that the model continues to be available for free under the previous gemini-2.5-pro-exp-03-25 model ID:
llm -m gemini-2.5-pro-exp-03-25 hi
The free tier is "used to improve our products", the paid tier is not.
Rate limits for the paid model vary by tier - from 150/minute and 1,000/day for tier 1 (billing configured), 1,000/minute and 50,000/day for Tier 2 ($250 total spend) and 2,000/minute and unlimited/day for Tier 3 ($1,000 total spend). Meanwhile the free tier continues to limit you to 5 requests per minute and 25 per day.
Google are retiring the Gemini 2.0 Pro preview entirely in favour of 2.5.
I've added a new content type to my blog: notes. These join my existing types: entries, bookmarks and quotations.
A note is a little bit like a bookmark without a link. They're for short form writing - thoughts or images that don't warrant a full entry with a title. The kind of things I used to post to Twitter, but that don't feel right to cross-post to multiple social networks (Mastodon and Bluesky, for example.)
I was partly inspired by Molly White's short thoughts, notes, links, and musings.
I've been thinking about this for a while, but the amount of work involved in modifying all of the parts of my site that handle the three different content types was daunting. Then this evening I tried running my blog's source code (using files-to-prompt and LLM) through the new Gemini 2.5 Pro:
files-to-prompt . -e py -c | \
llm -m gemini-2.5-pro-exp-03-25 -s \
'I want to add a new type of content called a Note,
similar to quotation and bookmark and entry but it
only has a markdown text body. Output all of the
code I need to add for that feature and tell me
which files to add the code to.'Gemini gave me a detailed 13 step plan covering all of the tedious changes I'd been avoiding having to figure out!
The code is in this PR, which touched 18 different files. The whole project took around 45 minutes start to finish.
(I used Claude to brainstorm names for the feature - I had it come up with possible nouns and then "rank those by least pretentious to most pretentious", and "notes" came out on top.)
This is now far too long for a note and should really be upgraded to an entry, but I need to post a first note to make sure everything is working as it should.
Introducing 4o Image Generation. When OpenAI first announced GPT-4o back in May 2024 one of the most exciting features was true multi-modality in that it could both input and output audio and images. The "o" stood for "omni", and the image output examples in that launch post looked really impressive.
It's taken them over ten months (and Gemini beat them to it) but today they're finally making those image generation abilities available, live right now in ChatGPT for paying customers.
My test prompt for any model that can manipulate incoming images is "Turn this into a selfie with a bear", because you should never take a selfie with a bear! I fed ChatGPT this selfie and got back this result:
{kind=link}

That's pretty great! It mangled the text on my T-Shirt (which says "LAWRENCE.COM" in a creative font) and added a second visible AirPod. It's very clearly me though, and that's definitely a bear.
There are plenty more examples in OpenAI's launch post, but as usual the most interesting details are tucked away in the updates to the system card. There's lots in there about their approach to safety and bias, including a section on "Ahistorical and Unrealistic Bias" which feels inspired by Gemini's embarrassing early missteps.
One section that stood out to me is their approach to images of public figures. The new policy is much more permissive than for DALL-E - highlights mine:
4o image generation is capable, in many instances, of generating a depiction of a public figure based solely on a text prompt.
At launch, we are not blocking the capability to generate adult public figures but are instead implementing the same safeguards that we have implemented for editing images of photorealistic uploads of people. For instance, this includes seeking to block the generation of photorealistic images of public figures who are minors and of material that violates our policies related to violence, hateful imagery, instructions for illicit activities, erotic content, and other areas. Public figures who wish for their depiction not to be generated can opt out.
This approach is more fine-grained than the way we dealt with public figures in our DALL·E series of models, where we used technical mitigations intended to prevent any images of a public figure from being generated. This change opens the possibility of helpful and beneficial uses in areas like educational, historical, satirical and political speech. After launch, we will continue to monitor usage of this capability, evaluating our policies, and will adjust them if needed.
Given that "public figures who wish for their depiction not to be generated can opt out" I wonder if we'll see a stampede of public figures to do exactly that!
Update: There's significant confusion right now over this new feature because it is being rolled out gradually but older ChatGPT can still generate images using DALL-E instead... and there is no visual indication in the ChatGPT UI explaining which image generation method it used!
OpenAI made the same mistake last year when they announced ChatGPT advanced voice mode but failed to clarify that ChatGPT was still running the previous, less impressive voice implementation.
Update 2: Images created with DALL-E through the ChatGPT web interface now show a note with a warning:

Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Notes on Google’s Gemma 3

Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]Here’s how I use LLMs to help me write code

Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—how come some people are reporting such great results when their own experiments have proved lacking?
[... 5,178 words]What’s new in the world of LLMs, for NICAR 2025

I presented two sessions at the NICAR 2025 data journalism conference this year. The first was this one based on my review of LLMs in 2024, extended by several months to cover everything that’s happened in 2025 so far. The second was a workshop on Cutting-edge web scraping techniques, which I’ve written up separately.
[... 2,797 words]Cutting-edge web scraping techniques at NICAR. Here's the handout for a workshop I presented this morning at NICAR 2025 on web scraping, focusing on lesser know tips and tricks that became possible only with recent developments in LLMs.
For workshops like this I like to work off an extremely detailed handout, so that people can move at their own pace or catch up later if they didn't get everything done.
The workshop consisted of four parts:
- Building a Git scraper - an automated scraper in GitHub Actions that records changes to a resource over time
- Using in-browser JavaScript and then shot-scraper to extract useful information
- Using LLM with both OpenAI and Google Gemini to extract structured data from unstructured websites
- Video scraping using Google AI Studio
I released several new tools in preparation for this workshop (I call this "NICAR Driven Development"):
- git-scraper-template template repository for quickly setting up new Git scrapers, which I wrote about here
- LLM schemas, finally adding structured schema support to my LLM tool
- shot-scraper har for archiving pages as HTML Archive files - though I cut this from the workshop for time
I also came up with a fun way to distribute API keys for workshop participants: I had Claude build me a web page where I can create an encrypted message with a passphrase, then share a URL to that page with users and give them the passphrase to unlock the encrypted message. You can try that at tools.simonwillison.net/encrypt - or use this link and enter the passphrase "demo":

State-of-the-art text embedding via the Gemini API
(via)
Gemini just released their new text embedding model, with the snappy name gemini-embedding-exp-03-07. It supports 8,000 input tokens - up from 3,000 - and outputs vectors that are a lot larger than their previous text-embedding-004 model - that one output size 768 vectors, the new model outputs 3072.
Storing that many floating point numbers for each embedded record can use a lot of space. thankfully, the new model supports Matryoshka Representation Learning - this means you can simply truncate the vectors to trade accuracy for storage.
I added support for the new model in llm-gemini 0.14. LLM doesn't yet have direct support for Matryoshka truncation so I instead registered different truncated sizes of the model under different IDs: gemini-embedding-exp-03-07-2048, gemini-embedding-exp-03-07-1024, gemini-embedding-exp-03-07-512, gemini-embedding-exp-03-07-256, gemini-embedding-exp-03-07-128.
The model is currently free while it is in preview, but comes with a strict rate limit - 5 requests per minute and just 100 requests a day. I quickly tripped those limits while testing out the new model - I hope they can bump those up soon.
Structured data extraction from unstructured content using LLM schemas

LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
LLM 0.22, the annotated release notes
I released LLM 0.22 this evening. Here are the annotated release notes:
[... 1,340 words]Introducing Perplexity Deep Research. Perplexity become the third company to release a product with "Deep Research" in the name.
- Google's Gemini Deep Research: Try Deep Research and our new experimental model in Gemini, your AI assistant on December 11th 2024
- OpenAI's ChatGPT Deep Research: Introducing deep research - February 2nd 2025
And now Perplexity Deep Research, announced on February 14th.
The three products all do effectively the same thing: you give them a task, they go out and accumulate information from a large number of different websites and then use long context models and prompting to turn the result into a report. All three of them take several minutes to return a result.
In my AI/LLM predictions post on January 10th I expressed skepticism at the idea of "agents", with the exception of coding and research specialists. I said:
It makes intuitive sense to me that this kind of research assistant can be built on our current generation of LLMs. They’re competent at driving tools, they’re capable of coming up with a relatively obvious research plan (look for newspaper articles and research papers) and they can synthesize sensible answers given the right collection of context gathered through search.
Google are particularly well suited to solving this problem: they have the world’s largest search index and their Gemini model has a 2 million token context. I expect Deep Research to get a whole lot better, and I expect it to attract plenty of competition.
Just over a month later I'm feeling pretty good about that prediction!
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.